 English
English
资源说明:Git Workflows - release management, remote collaboration, and svn transitions
# Git Workflows by [Yan Pritzker](http://yanpritzker.com)
## Why use git?
Git is an extremely powerful source control system. Its power lies in its speed and flexibility, but this can also be a point of confusion for many new users. Git is unfortunately quite inconsistent in its syntax, and exposes many of its not-so-friendly internals to the outside world, sometimes to the detriment of usability.
As many systems built by hardcore engineers (Git came from Linux kernel hackers), if wielded by a wizard, it can be used to achieve many great things, but can be initially confusing even for seasoned developers. This book bypasses the ugly internals of git and gets to the heart of improving your development workflows by using git.
If you've picked up this book, it's likely you're already convinced that git is great. For a great overview, check out http://whygitisbetterthanx.com. To sum it up, the following are my favorite features of git, which this book will focus on.
### Offline productivity, speed, and multitasking
Git encourages multitasking and experimentation. Fast and easy local branching means the ability to keep bugs and features you're working on in different workspaces, and to experiment more with throwaway branches. Having everything local means you can have fast diffs and history logs, and commit to your repo while on the go without being online.
### Remote collaboration and code review
The ability to pull down other people's changesets for code review and collaboration is made easy with git's multiple remotes capability. Being able to create cheap local branches and experiment with integrating other developer's changesets makes it ideal for open source projects and outsourced collaboration with junior developers, where you want to review other people's code before it becomes part of the master branch. And because anyone who has access to a repo can clone it, they can do development on a fork without asking for your approval, which also encourages experimentation.
### Changeset cleanliness
How many times have you tried to trace down a feature across many commits, or even worse, tease apart changesets that are clusters of unrelated features? Git offers multiple ways to keep changesets clean, from the index/staging area, to topic branches, to amending commits and completely rewriting your commit history. It's amazing what clean changesets can do to save you time in code review and release management.
### How is this book different from other git books?
Many git books explain git from the bottom up, starting with its internals.
Although git sometimes has many ways of doing the same thing, this book will
ignore some of the more obscure or advanced features of git in favor of using a
basic set of tools to get things done. It's an opinionated book, offering you
my own view on how things should be done based on my experiences with git.
Many newcomers to git make the mistake of not taking the time to understand what git does, treating git like their old centralized source control system, and getting frustrated by the number of commands they have to remember to work with new concepts like the index (staging area), their local repo, and remote repos.
If you create a model in your head of what git is doing, you'll be quickly on your way to mastery. Understanding what's happening under the hood relieves you of the burden of having to memorize commands that seemingly make no sense at the outset. It's like understanding how a formula is derived instead of memorizing the formula. Once you understand the model, it will become second nature to work with the various parts of your git repository.
If you are new to git, I highly urge you to read at least one of the following resources:
* [Pro Git Book](http://git-scm.com/book)
* [Git Internals by Peepcode](https://peepcode.com/products/git-internals-pdf)
As the Peepcode book says, "Git != Subversion + Magic!". This is an important mantra that everyone reading this book should understand. Commit some time to learning what git does, and you will be rewarded. However, if you do decide to bypass the intro books, this book will give you enough of an overview so that you can dive right in. It will also provide you with a handy list of aliases making certain features of git easier to work with.
There are also many great cheatsheets availble on the web including:
**Chapter 1** will start with a brief review of how a git repository is structured. You'll also get your git environment set up with some enhancements to your bash prompt, and be given a simplified git alias list that will help you work with git on a daily basis without remembering obscure command line switches.
**Chapter 2** will teach you to treat your changesets like you do your code, by keeping them clean, cohesive, and refactoring them when needed. You'll learn to use topic branches as workspaces to work on multiple features or bugs, and to combine or tease apart changes to keep patch history clean.
**Chapter 3** shows you how to use your repository history to jump back and forth between different commit states, revert changes, and search the repository for commits.
**Chapter 4** talks about remote collaboration and code review. You'll learn about remote branches, using GitHub and its forking system, and doing remote pair programming by sharing your branches with your team.
**Chapter 5** focuses on release management including tagging, branching, and cherry picking commits between dev and release branches.
**Chapter 6** is about introducing git into your organization through an unobtrusive bottom-up process, and using git while everyone else is using subversion.
## Chapter 1 - Setup & Repo Overview
If you're familiar with subversion, you're used to one central repository, which everyone interacts with by pulling and pushing changes. While you can use git in this way (something we'll talk about in Chapter 3), there are many fundamental differences to understand.
With git you always have the entire repository in your hands, including all its history, branches, and tags. A git project starts in one of two ways. Either you create the repo locally using `git init`, or you start working on someone else's existing project by using `git clone [repo url]`.
Let's examine the three basic components of a git project tree:
### The Repository
The basic unit that git works with is the *changeset* (also called a *patch*). Almost all git commands have to do with operations on changesets, not on files. Keep this in mind if coming from a subversion background. Every git changeset is identified by a SHA-1 hash which looks like this: c15724ef2b99852564a92f9d90c93f9cb6e037ff. The hash is a unique reference to a particular set of changes on a particular branch, and is unique across your repository. Most of the time the first five or so characters of the hash are unique enough to identify it. So you'll sometimes see people abbreviate changeset id's by giving you just the short hash.
Unlike subversion, which litters every directory in your tree with its metadata files, the entire git repo lives in one directory called `.git` at the top level of your project. Without going into too much detail, this directory contains a list of *objects* which are binary representations of your changesets, and a list of *refs* which are the human names you use to refer to your branches and tags. I recommend poking around the `.git` directory to see what's inside. Most of it is human readable and very educational.
If you've just started or cloned a git project, you'll find you typically have a branch called *master*. There is nothing special about this branch other than it's the conventional way to name the main development branch — the rough equivalent of *trunk* in subversion. Git branches are nothing more than human names for a particular changeset. To verify this, just take a look at the file `.git/refs/heads/master`. Inside, you'll see the hash that identifies the latest commit in your repository on the master branch.
### The Working Tree
The working tree is the set of files you're currently working with. To start working on something in your git project, you first `checkout` a particular branch from your repository. When you checkout code, you specify the name of a branch you'd like to work with, and the files in your working tree are replaced with the files from the branch. The files in your working tree are literally overwritten by your checkout – but not to worry. Git will not let you do something stupid like overwrite your changes with a checkout. If your working tree is dirty, git will warn you that checking out a particular branch will overwrite your changes and prevent you from doing so. We'll talk about how to deal with this later.
### The Index
There is a place interchangeably known as the index, cache, or staging area. This is where you put your changes before they are ready to be comitted to the repository. You'll learn more about the index in Chapter 2, but for now just think of the index as a place that lets you selectively commit changes you make. For example, if you've made a set of file modifications, but it turns out they are two unrelated changes, you can add the appropriate half first to the index, make the commit, and then add the second half and make another commit.
A great image of the git workflow and all the parts of the repo is at :
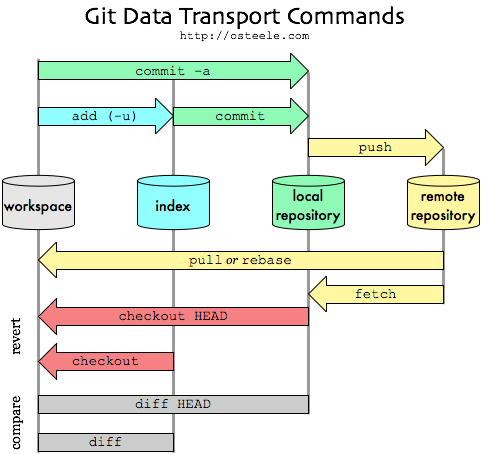
For more introduction to how git works, please see PeepCode's Git Internals book.
An excellent environment is the first step to enjoying a new tool. Below are several modifications I recommend to a default git setup in order to increase its usability. This chapter explains each modification and alias, but if you'd rather just grab the entire file, it's available in Appendix A.
### Git bash completion
So that you don't have to type out branch names and other things, locate the file *git-completion.bash* and add it to your startup scripts so that it executes. This typically involves adding a line to ~/.bashrc:
. /path/to/git-completion.bash
If you can't locate the file, try [downloading git-completion.bash](http://repo.or.cz/w/git.git?a=blob_plain;f=contrib/completion/git-completion.bash)
### Show the git branch in your bash prompt
It's very helpful to know which branch you're on at any given time to prevent mistakes. Simply place the following code in your .bashrc and enjoy. Here I've supplied the prompt line (PS1) from my own terminal, but feel free to modify yours as you see fit, inserting the call to $(_\_git\_ps1) wherever you want the branch to appear.
export PS1='[33[01;34m]u:[33[01;32m]w[33[00;34m][33[01;32m][33[00m][33[01;33m]$(__git_ps1)$ [33[00;37m]'
via [asemanfar.com](http://asemanfar.com/Current-Git-Branch-in-Bash-Prompt)
Now, let's make a couple modifications to our ~/.gitconfig to enhance the git experience.
### Get colorized
It's important to make working with git easy on the eyes. Turn on colors to see diffs, status, branches, etc in color.
[color]
diff = auto
status = auto
branch = auto
interactive = auto
ui = auto
### Automatic cleanup and compression of the repo
Git needs periodic maintenance to make it run fast. Here's a way to avoid ever having to think about it by making it run automatically.
[gc]
auto=1
### Better merge messages
By default, when you merge a branch in git, you get a fairly meaningless message like *merge branch 'master' of git@github.com:name/project*. To get a summary of the changes you're merging, turn this option on:
[merge]
summary=true
It's also handy when doing `cherry-pick` to copy changes from one branch to another, to have git automatically put the original commit hash into the commit comment. Here's an alias for doing this:
[alias]
cp = cherry-pick -x
### Better information on branches and remotes
By default, the git `branch`, `remote`, and `tag` commands give you lists of things, but no information about them. Here are some aliases that do a little better.
[alias]
b = branch -v
r = remote -v
t = tag -l
### Two useful aliases: unstage and uncommit
There are many other aliases given in the .gitconfig included in the Appendix, but these two are aliases for otherwise hard to remember commands.
[alias]
unstage = reset HEAD
uncommit = reset --soft HEAD^
This is a case of git doing completely different things depending on switches given to the reset command. This powerful command can be used to throw away commits, or time travel to previous states. While it will be discussed more in Chapter 2, let's look at these aliases.
`unstage` is the opposite of `git add`. It lets you remove items from the staging area. This makes it a very useful tool when you're deciding which files to stage for a commit. If you've accidentally added something to the staging area, just use `unstage` to remove it.
`uncommit` is a technique I often use. It removes the last commit from your repository, and puts the changes into your index. It's like going back in time to the moment right before you committed. This is a useful technique in resuming work on an unfinished changeset. But please don't do it if you've already pushed this changeset to a place where someone may have pulled it from, because you'll be changing the commit history in a nonlinear way.
These aliases and their usage are discussed in detail in Chapter 2.
For more aliases, please see the appendix which includes the entire recommended .gitconfig.
Git provides a number of tools which can alter your commit history to clean up your changes after the fact, as well as tools to use prior to and during commit time to keep separate changes separate. I use this capability to maintain a *one changeset per feature, one feature per changeset* development philosophy.
This is important for two reasons: First, because it makes it easy for your fellow developers to see change history in one spot and do simple code reviews without tracking a bug or feature across many commit sets. Second, because it simplifies constructing selective releases on the fly (picking a specific set of bugs and features to be included into a new branch).
## Chapter 2 - Keeping Your Changsets Clean
### Using the index for breaking apart quick changes
Before we get to topic branches and keeping different workspace for your bugs and features, let's take a look at a quick way to create separate commits from a single set of changes.
### Making several commits from one set of changes
Let's say you've been hacking away for a couple hours and now you've got two different sets of changes in your working tree. We run `git status` to see what's available.
# On branch master
# Changes not staged for commit:
# (use "git add ..." to update what will be committed)
# (use "git checkout -- ..." to discard changes in working directory)
#
# modified: public/file1
# modified: public/file3
#
# Untracked files:
# (use "git add ..." to include in what will be commited)
#
# file2
Unlike many of git's obscure error messages, the status screen is actually very friendly and explains what to do. On the status screen above we see we have modified two files and added a new file. But it turns out that 'file1' and 'file3' are part of a bugfix, and 'file2' is an unrelated change. Using the color settings outlined in Chapter 1, you'll see the files shown in red, indicating that they are not yet staged for commit.
We stage a change for commit by adding it to the index. Because git operates on changes, and not on files, it's easy to add all changes in a particular directory:
git add public
This adds the changes made to file1 and file3 to the index (interchangeably referred to as the staging area). I could also do it by listing the files after the add command, or by issuing multiple add commands. If I wanted to add all available changes I could simply use `git add .` After running the command, the status shows:
# On branch master
# Changes to be committed:
# (use "git reset HEAD ..." to unstage)
#
# modified: public/file1
# modified: public/file3
#
# Untracked files:
# (use "git add ..." to include in what will be committed)
#
# file2
You'll notice that the files that are added to the index, under "Changes to be committed" are now colored green instead of the previous red. Now to commit the two changes that have been staged, we issue the commit command:
git commit -m "This is my commit msg"
Now we're left with the change to file2 in our working tree, and we can follow the same procedure to commit the one file.
**Note:** Some beginning git tutorials encourage you to use the syntax `git commit -a -m` to bypass the index and commit all changes. I recommend *never doing this* because it is very easy to mass commit unrelated changes. Always use *git status* to find out what's been changed, and selectively add files to the index before committing.
### Using `git add` for deleted files
One slightly annoying thing about `git add` is that it does not take into account deleted files. Typically, git would like you to use `git rm` to delete files, but in practice, using command line or IDE you are likely to delete files using traditional methods.
To add deletions to the index, a handy shortcut is `git add -A`, which tells git to add all files it knows about, including deletions.
### Staging unrelated changes within one file
Git can also help you tease apart unrelated changes within one file, and add them selectively to the index. I find that I use this rarely because I try to work on separate changes in separate branches, but if you do find yourself in this scenario, git makes it easy:
git add --patch
This will launch an interactive prompt which will go through each change in each unstaged file and ask you whether you want to stage the hunk in question. Simply answer the questions, and when you're finished you will see that the file is both in the staged and unstaged areas of the status output. To see which changes are staged, we use
git diff --cached
The `--cached` argument means we're working with the index. Strangely this is probably the only place in git that refers to the index as a cache. Effectively this command says "give me the difference between the cache (index/staging area) and the HEAD (last commit)". You can also do a diff for the unstaged changes:
git diff
Note that this diff does *not* include the staged changes. This is a handy way to see the differences in both areas. Use this a couple times alongside `git status` and you should get a grasp on the technique pretty quick. I use the aliases `d` for `diff`, and `dc` for `diff --cached`, so that it's easy on the fingers.
Of course, diff takes more arguments, so that you can compare to something other than HEAD (like another branch, say) and is quite flexible. For more info, see the EXAMPLES section of the `git diff` manpage.
### Using topic branches
Though the methods described above are good for quick hacks, when working on larger bugs or features, you can start to use branches to separate your work into workspaces and work on multiple things without them interfering with each other.
### One branch per bug
Whenever you start to work on a feature or a bug, create a new branch locally. This branch will live for the duration of the work you do, and then we'll squash it into one clean changeset back into the master, following our *one commit per feature* philosophy.
git checkout -b bug123 master
Work on bug fix 123, making commits as you go. Realize that you actually need to start work on feature456 now.
git checkout -b feature456 master
Work on feature456, make commits. Now go back to the bug.
git checkout bug123
Make some more changes. Now we're done, so let's bring these changes back to the master.
git checkout master
git merge --squash bug123
git commit
Don't you love squashing bugs? The `--squash` parameter brings in all the commits from the *bug123* branch as if they were one change. It also avoids logging the change as a merge, so it looks like you just made one clean commit with all the changes from the bug123 branch as one. Once you're sure you don't need the history of working on that bug anymore, delete the branch.
git branch -D bug123
I like to use the alias `nb` for new branch, so that the commands above become:
git nb feature123 master
Also note that if you're creating a branch from the branch you're currently on, then the second argument can be omitted, so if you're on the master branch already, simply use:
git nb feature123
### Coming back to unfinished work on a topic branch
Let's say it's Friday afternoon and you're halfway through a refactoring but you want to save it until next week. A good way to remember that it's unfinished work is to log it in the comments. Simply commit your changes with a helpful message:
git commit -a -m "uncommit me: need to finish stuff in the user model"
Note that above we used the `-a` switch which tells git to automatically stage all your changes. It's as if you ran `git add .` right before the commit. When you come in on monday, you can see your list of available branches:
git branch -v
* bug123 937c391 uncommit me: need to finish stuff in the user model
And remembering that you were working on bug123, you check out the branch to resume work:
git checkout bug123
git uncommit
The `uncommit` alias is covered in Appendix A, and is the aliased to `git reset --soft HEAD^`. Effectively, it takes you back in time to the moment right before you made the commit, with all of your changes still in the index. This means you can now examine your changes and modify them if necessary and commit again.
### Fixing the last commit
The uncommit command above shows you how to resume work on a previously committed changeset. If you're simply adding a couple files or changing the commit comment on your last changeset, a quicker way to do this is `git commit --amend`, or using the alias `git amend`.
As usual, you'll have to `add` your changes to the index before you do this. The amend command will not create a new commit, instead it will modify the last commit. **WARNING:** never do this to a commit that you've already pushed to a remote repository.
### Using the stash to temporarily hide your changes
Using uncommit is my favorite way of resuming long running work, but if you're working on something and a production bug comes in that takes priority, you can quickly toss your changes into a place git calls the *stash*. You can think of it as a temporary branch that works like a stack. Every time you type `git stash`, your changes are removed from your working tree, restoring your files to the last checked out state, and the changes are saved as a changeset on the stash.
You can then pop your changes off the stash by using `git stash pop` or `git stash apply` to apply the change without popping it off the stash. Use `git stash list` to see the contents of the stash.
# do some work, prod bug comes in
git stash
git checkout prod_branch
# fix your prod bug and commit
git checkout master
git stash pop
Another good use of the stash is for moving uncommitted between branches. Sometimes you start to work on something on master, or on another branch and realize the work probably needs to be moved over to a branch of its own. While you can sometimes checkout another branch and the changes will automaticaly transfer over, occasionally your changes conflict with the code on the branch, so the correct way to do this is to *stash* the changes, checkout the new branch, and then unstash them.
### Keeping a topic branch in sync with its parent
When you've wandered off for a while on your topic branch, working on your bug or feature, you'll occasionally want to grab updates that have been made in the master branch, or wherever you branched from. The best way to do this is to use the `rebase` command. The functionality of rebase is best illustrated with a diagram from the git manpages:
Assume the following history exists and the current branch is "topic":
A---B---C topic
/
D---E---F---G master
From this point, the result of either of the following commands:
git-rebase master
git-rebase master topic
would be:
A'--B'--C' topic
/
D---E---F---G master
So what rebase does is stash your changes, grab the latest from master, and then apply your changes on top. This effectively makes it as if rather than branching several days ago, you just branched now from te tip of the master and made your commits there.
Most of the time, this will work without a hitch. However, you may occasionally get a merge conflict if the same file has been modified in the same place on both branches. If this happens, git will complain with a very loud and verbose error message. The important thing with git is always to read the end of the message. You will then see that it tells you to resolve the conflict and then `git rebase --continue` or `git rebase --abort`.
### Changing commit history to clean up change sets
**WARNING:** you should never alter commit history after you have pushed your changes to a remote repository.
If you've been following the above techniques and keeping your work in separate branches, squashing full changesets into master, you'll hopefully never have to do interactive rebasing. However, one scenario where this technique is useful is when you've pulled a large set of changes from another repo (more on working with others in Chapter 4).
Your friend may not have been following the clean changeset philosophy as you have, so you'd like to fix the commits you just pulled from him by fixing some commit messages, maybe edit some of the code in one of the commits, and perhaps combinging some of his commits into larger changesets.
The `rebase -i` command is a powerful way to gain editorial capabilities over your last N commits. To launch it, use the following syntax:
git rebase -i HEAD~[N]
Substituting `[N]` for the last N commits that you want to work with.
Once you have done this, you'll be presented with an editor screen with instructions. It will look something like this:
```
pick 06e0e1a (dev) Add query stats at top of page for dev/devcache
pick 850150f (dev) Disable newrelic in test01 and dev01
pick 737b01b Ticket #1606 - error while accessing /db_admin/available_distro
# Rebase 5926a38..737b01b onto 5926a38
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
#
# If you remove a line here THAT COMMIT WILL BE LOST.
```
The screen offers a clean set of instructions to follow. Simply edit the file and change the word 'pick' to 'edit' if you want to change the commit in any way. Once you've decided which commits you'll be working with, git will exit the screen and begin taking you through every commit. At every stage, make sure you read the directions which are pretty simple. You will have the opportunity to edit any commit you want, and commit it again. Once you have done so, `git rebase --continue` will take you to the next commit on your list until you're done.
You can [learn more about interactive rebasing at git-scm.com](http://book.git-scm.com/4\_interactive\_rebasing.html)
With git, you've got the entire codebase history in your hands. Did you ever want to go back to yesterday's state, or last week before you broke a particular feature? Git makes it not only easy, but very fast. Let's look at a couple use cases.
## Chapter 3 - Time Traveling for Fun and Profit
### Searching for a specific change
If you're looking for a changeset and you remember you messed with an object called "foo\_bar\_baz" but don't remember quite when, you can search for it using the log. The `-p` parameter tells git to print the actual contents of the patch so you can see the changes.
git log -p -S"foo_bar_baz"
If you know you made the change last week and want to save some time in the search, git understands english timeframes:
git log -p -S"foo_bar_baz" --since="1 week ago"
If, on the other hand, you want to search for a commit message (really handy if you put issue tracking numbers into your commit messages, something I highly recommend):
git log -p --grep="Ticket #382"
### Throwing away all changes
If you've made a mistake and want to go back to your last checkout, ignoring anything that's in the working tree or index.
git checkout -f
### Restoring a file or directory to a past state
The most basic type of time traveling is grabbing a set of changes from your HEAD. Let's say you made some changes to a file (in this case, a README) that just aren't working. Let's throw those away.
git checkout README
But what you're really doing here, is checking out the file from your HEAD (equivalent to `git checkout HEAD README`). You can also check out the state of the file from any given commit:
git checkout c5d563fae README
Now we've gone and grabbed the file from that particular commit set. Since branches and tags are just labels for particular commit hashes, we can also do the same thing use branch names.
git checkout experimental_branch README
But what if you know the file was working last week, now it's broken, and you want to take a look at what it was like? Easy:
git checkout "@{1 week ago}" README
When you grab a file from a previous time, it sits in your index, modified. So we can take a look at it:
git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD ..." to unstage)
#
# modified: README
#
And we can see what differences it has with the current version:
git diff --cached
We use --cached because the file is in the index.
### Throwing away commits
If you've done something unsavory in your repository and want to really reset your state, you can use `git reset --hard` which is actually equivalent to `git checkout -f`. Used without parameters, it resets your working tree and index to HEAD, which effectively gets rid of any changes.
Let's say you committed or pulled in 3 commits and now you realized you no longer want them:
git reset --hard HEAD~3
This command tells us to revert the repository state to that of 3 commits ago. **Note:** this will effectively throw away your last 3 commits and reset your current branch's HEAD to point to HEAD~3, 3 commits ago.
### Reverting a changeset
As we learned in Chapter 2, while working with our local repo we have a number of tools including merging, squashing, and interactive rebasing which can help us organize our changes. Once you've pushed changes to a remote repository, it is considered dangerous to modify the history because someone else may have already pulled it.
However, git offers you an easy way to undo a patch by committing a change that effectively reverses the patch in question. The simplest usage is to revert an entire changeset:
git revert 850150f
This creates a patch that is the opposite of changeset 850150f and commits it to your repo.
### Reverting changes to one file only
This slightly more advanced workflow using `revert` lets you undo the changes to one file only. We'll do this by asking git to create the reverting changeset but not commit it, and modify it before it goes in. First, we'll figure out which changeset it changed in:
git log filename
Revert that changeset without committing it. This will put the reversion into your index.
git revert -n [hash]
Since we only want to revert the one file, we'll unstage all the changes.
git unstage
And now we'll stage just the file we're interested in.
git add filename
git commit -m "Reverting change to file"
Now we'll just throw away the rest of the changes, which we don't care about:
git checkout -f
## Chapter 4 - Remote Collaboration and Code Review
Git is great for remote collaboration because of several factors:
* As long as people have read access to your repo, they don't need your permission to clone it and do their own work on their fork. Having their own fork also means they can maintain their own branches without polluting the main repository with personal experimental branches.
* It is easy to pull in work from team mates, and because of cheap branching it's easy to experiment before committing results to the main repository. Because branching is easy, git encourages code review by using branches before the code goes into the master branch.
* GitHub provides an excellent service that helps you track who has cloned your repository and what work they've done. It also offers fantastic per-line code review capabilities.
Here we'll take a look at a couple common ways of sharing work using git. This chapter will assume you have an account on GitHub, and that you're using GitHub as your central repository, through which everyone collaborates.
### Using git remotes for collaboration
While it's possible to use git completely by yourself, without a remote repo, it's much more useful in a collaborative environment. While there are myriad ways you can use git remotes, I am going to advocate a specific approach that I have found works well:
* All code is hosted on and shared through GitHub. There will be no peer to peer sharing (grabbing code directly from someone else's repository hosted via git-daemon or similar).
* Only some team members have direct commit access to your project (we'll call them the *core committers*).
* Some team members are junior developers or outsourcers whose work is reviewed by and merged in by the core committers (we'll call them *contributors*).
This chapter will illustrate how to collaborate on code creation with this sort of team. If your organization uses either a pure core committer model, or pure contributor model, you can still pick and choose the parts of the workflow that make sense to you.
### Set up your remote at GitHub
The first thing you'll do is setup your repository on GitHub (http://github.com). If you are working for a company, I recommend setting up the account in the company's name so that contributors know that it's the official repo for the project. Each developer should have his own personal GitHub account (using the free account is fine), which he will use to either contribute directly, or fork the main repo.
Create a new project, and follow GitHub's instructions for pushing your changes out to your newly created repo. If you already have a git repo, the steps typically look like this:
First, add a *remote* (git's term for a remote repo) called *origin* (this is simply a convention for the primary repo that you push to and pull from).
git remote add origin git@github.com:[username]/[repo-name].git
You can always see all the remotes you have:
git remote -v
Once you have the remote, you'll push the code you have out:
git push origin master
This command tells git to push all the changes you've made on your *master* branch, to the *master* branch on the remote called *origin*. It's actually a shortcut syntax. Because your local and remote branches are both named *master*, you don't have to specify the remote branch name. If you wanted to call your local branch *foobar* instead, you could use the syntax
git push origin foobar:master
Git offers a secondary shortcut convenience. If you name all your local branches identically to your remotes, then you can just use:
git push
This will push out changes on all branches that have matching branches on the remote end.
**Note:** You should take a look at the file called .git/config. This file lists all your branches and remotes, and has interesting information that will help you learn about what git does internally to track your branches and their relationship to remotes.
### git-remote-branch, a handy automation for remote branches
Git is pretty low level when it comes to managing local and remote branches and keeping them in sync. Enter git-remote-branch: a great tool that helps you automate day to day operations on remote branches. As a bonus, it shows you exactly what it's doing under the hood so you can learn more about how git works. The rest of this chapter will assume you have git-remote-branch installed, and are using the `grb` command.
Homepage: http://github.com/webmat/git_remote_branch/tree/master
Installation (you will need rubygems for this):
sudo gem install git_remote_branch --include-dependencies
Once you've installed the tool, go ahead and run `grb` without arguments to see the help.
### Creating and pushing to remote branches
If you're working on a long lived topic branch for a particular feature, it's a good idea to back it up to your remote. It's also useful to push it out to the remote so that others can look at it and collaborate with you. To push an existing branch to the remote:
git push -u origin [branchname]
If you haven't yet created the branch,
git checkout [branchname]
Which both creates the local branch and pushes it to the remote.
### Deleting a remote branch
When you're done with an experimental branch, you delete it locally with:
git branch -D [branchname]
But your branch is still active on the remote. To delete it, git has a slightly obscure syntax
git push origin :[branchname]
Of course, `grb` makes it much simpler to do both in one shot
grb delete [branchname]
### Pulling changes from a remote
The opposite of push is a pull, and allows you to grab code that someone else has committed. The pull is done in two steps. The first step, `fetch`, downloads code from the remote repo into your local git repo (the directory called *.git*, NOT your working tree).
The second step is getting the changes from the remote branch into your local working tree by using either `merge` or `rebase`. Let's take a look at how this works.
Suppose you're working on a branch called *bug123* at your github repository. A coworker has committed changes to the branch that you wish to pull in.
First, we fetch the latest changes from the remote repo. This will download *everything* in the remote repo into our local repo. This includes all remote branches. Remember that with git, you're storing the entire repository locally.
git fetch origin
To show all the branches we now have, use:
git branch -av
The `-a` tells us we want to see all branches (including remote ones, you can see *only* remote branches by using `-r`), and the `-v` gives us information about the latest change on each branch. Note that the branches listed as "origin/[branchname]" are called *remote tracking branches*. Think of these branches as local read-only mirrors of the remote repo.
If you ever try to check out a remote tracking branch directly:
git checkout origin/master
You will get a warning from git that looks like this:
Note: checking out 'origin/master'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example:
git checkout -b new_branch_name
HEAD is now at b574c5f... Merge pull request #10 from Mouseion/pro-git
So in order to actually work with the remote branch, we'll need a local tracking branch set up to track the remote branch in question:
git checkout -b bug123 origin/bug123
Which will result in the following message from git:
Branch bug123 set up to track remote branch bug123 from origin.
Switched to a new branch 'bug123'
### Pulling changes using merge
Once you've fetched all the remote branches and opened up the local tracking branch you want to work with, you'll merge the latest changes from the remote:
git merge origin/bug123
To automate the fetch and merge steps, git offers a `pull` command that does both in one shot:
git pull origin bug123
**Note:** whenever you merge, a commit message will be left in your local repo indicating the merge. This is because to git, there is no such thing as a central repo. Even if you and your team are using github to collaborate, each of your individual repos is treated as an equal, and merges are logged there just as they are anywhere else.
When working on long lived branches where multiple developers are constantly syncing up to it, I dislike merge commits because they dirty your repo history with essentially meaningless messages. To avoid this, we can use rebase instead.
### Long lived remote collaboration using rebase
Remember `git rebase`, discussed in Chapter 2? This command lets you move your work to the tip of a branch as if you had just started the work from the tip. This can be used to keep in sync with a remote repo as well. Let's say you've been working on your branch *bug123* and have made 3 commits. Meanwhile your coworker has pushed 2 commits to *origin/bug123* (at github).
You can grab his changes, and replay your changes on top by using the same rebase technique:
git fetch origin
git rebase origin/bug123
There is no difference between this and the rebase usage covered in Chapter 2, other than that we're rebasing from a remote tracking branch. Git also offers a shortcut to pull in this manner:
git pull --rebase origin bug123
If this is the way you prefer to work, you can have git always rebase instead of merge your pulls by editing your *.git/config* file for the branch in question:
[branch "master"]
remote = origin
merge = refs/heads/master
rebase = true
**Note:** as before, make sure you understand what you're doing with rebase. It will rewrite your commit hashes, so if you've pushed your code out to one place and rebase from another, you'll be in trouble. However, if you use rebase as recommended here, to sync with only one GitHub repository, you will have no problems.
### Core committer collaboration workflow
So, now that we know how to use `git pull --rebase`, let's take a look at a typical scenario in collaboration between two core committers, Alice and Bob, who work for BugFreeCode, Inc. working on a bug together: 1. Alice creates a branch and makes commits 2. Bob pulls her changes and makes additions 3. Alice pulls Bob's changes 4. Alice squashes bug into master and closes the branch
Alice starts working:
grb create bug123
# hack, hack, hack
git commit -a -m "Bug #123 fixed, needs code review"
git push origin bug123
She then asks Bob to do a code review on the branch. Bob pulls in Alice's changes:
git branch bug123 origin/bug123 # first time only
git checkout bug123
git pull --rebase origin bug123 # to sync it up
# hack, hack, hack
git commit -a -m "Bug #123 - Cleaned up alice's code"
git push origin bug123
Alice, who is the owner of the bug, now decides the bug is good to go, and merges it into the *master* branch, which their team uses as a starting place to create releases.
git checkout bug123
git pull --rebase origin bug123
git checkout master
git merge --squash bug123
git commit -m "Bug #123 - fixed all sorts of stuff. Thanks to Bob for the help."
git push # update the remote master branch
Since the bug is now in master, if there is no long term need to keep its history around, Alice deletes the branch from her local repo, and the remote.
grb delete bug123
### Squashing for code review
If Alice has made ten changes while working on her new feature, we'll call *feature-x*, and she wants her team to review her work, it is easier to review it as one cohesive changeset. While the *bug123* branch is still useful to track the history of the work on the bug as she debugs it with Bob, she only wants to show the one finalized changeset:
Using the `merge --squash` technique discussed in Chapter 1, we can create a changeset that will combine all her changes into one. By pushing this changeset out to GitHub, you can get a nice way to do code review with GitHub's line-by-line comment feature.
I like to add *-squashed* to the end of the branch name so that I know it's a temporary branch meant just for reviewing commits. Below, we create a branch called *bug123-squashed*, branched from *master*, and create a squashed changeset, pushing it out to GitHub.
grb create bug123-squashed
git merge --squash origin/bug123@
git commit -m "Bug #123 - squashed commit for code review"
git push
Now, Alice can refer her team to the GitHub url for the changeset, and collect comments using the web interface at GitHub, or coworkers can directly checkout the *bug123-squashed* branch and use `diff` and `show` commands to inspect it.
### Outside contributor collaboration workflow
While Alice and Bob work together by directly committing to the GitHub repo, they outsource part of their project to contributor Charlie. Alice is the project leader, so she takes on the primary task of reviewing Charlie's work, and merging it into the main repository.
The workflow recommended for outside contributors is as follows, using Alice as an official core committer, and Charlie as the contributor
1. Charlie creates a branch for every feature or bug
2. Charlie has a remote repo link to the official repo
3. Alice examines code committed by Charlie, adds her own changes
5. Alice merges Charlie's changes into the official *master*
6. Charlie pulls changes from official *master* into his own *master*
You already have all the tools you need to execute this workflow. Let's walk through it.
### Setting up remote contributor forks
First, Charlie signs up for his own GitHub account. He then visits the project's homepage under the company's GitHub account, and clicks the Fork button. This button creates a clone of the repo for Charlie under his own account.
GitHub offers a nice feature for fork network tracking and visualization which is probably worth the price of admission alone. The company can now look at who has forked the project, and what kind of commits they have made. This makes it easy to know when something is worth pulling in.
Once Charlie has his fork, he follows the instructions provided by GitHub to clone the fork on his local machine, which looks something like this:
git clone git@github.com:charlie/some-project.git
Charlie now has an *origin* which refers to his own project on GitHub. But he's going to occasionally want to sync up to the official repo owned by BugFreeCode, Inc, so he'll add a remote for the original repo, as well:
git remote add bugfree git@github.com:bugfreecode-inc/some-project.git
### Taking a look at contributor's work
To track Charlie's progress, Alice sets up a remote link to Charlie's repo:
git remote add charlie git@github.com:charlie/some-project.git
git fetch charlie
She can then directly view branches using
git show charlie/bug123
Or, by using the techniques from the beginning of the chapter to create local tracking branches for contributing to Charlie's work:
git branch bug123 charlie/bug123
# hack, hack, hack - helping charlie out
git commit -a -m "code review and fixing to help Charlie"
git push charlie bug123
# once the bug is done, put it into master
git checkout master
git merge --squash charlie bug123
git commit -m "Bug #123 - fix something" --author "Charlie "
git push
Charlie keeps himself in sync to the official master branch by using `pull --rebase`:
git checkout master
git pull --rebase bugfreecode master
If Charlie does all his work on branches and never touches his master, another equivalent way, but perhaps slightly safer (avoiding any rebase troubles), is to reset to point to the master
git checkout master
git fetch bugfreecode
git reset --hard bugfreecode/master
### Giving credit to contributors
In the section above, notice the `--author` switch on the commit line. Git understands that the person committing is not always the person who wrote the code. By using this line, you will see the commit appear on GitHub with two users attached to it, which is a great way to give credit and track the real owner of the code for the future.
The nice thing is that git remembers authors, and you can use pattern matching in the future to specify an author. So to designate Charlie as the author, you can use `--author "cha"` in the future.
### Cleaning up stale remote tracking branches
Once you're finished collaborating on remote branch bug123, one of the developers will delete the remote branch, but everyone else will still have that branch listed in their `git branch -a` output. To remove any stale tracking branches that are already gone from the remote, simply use
git remote prune origin
Where *origin* is the name of the remote. Do this for every remote you have periodically to maintain a clean branch list.
### Dealing with conflicts during merges
When you merge another branch, you may occasionally get a CONFLICT if the code in the same place has been modified in ways that git cannot easily merge. Git will provide a warning message
git merge --squash origin/bugfix
CONFLICT (content): Merge conflict in app/models/foo.rb
There are two ways to deal with conflicts. I've found the easiest thing is to simply open up the file in question, and find the conflicting section. It will look something like this:
>>>>>> origin/bugfix:app/models/foo.rb
Simply edit the file to remove the ">>" markers, leaving the correct line of code in place. The other way to do this is to run `git mergetool`. This command will automatically launch whatever available merging utility you have on your system (typically FileMerge on OSX), and give you a graphical UI for picking one line or another. It's really a matter of personal preference but after some experience I found it's actually easier to understand the changes by looking at the file directly.
You'll also notice that the conflicted file didn't get added to the index, so once you've resolved all your conflicts, simply
git add .
To add all the changes to your index, and commit.
### Dealing with conflicts during rebase
TODO/UNFINISHED: rebase conflict management. git rebase -abort/-continue etc.
http://jdwyah.blogspot.com/2008/09/merging-with-git-conflicts.html
### Bonus: Serving up your local repo to a friend
While I strongly advocate using a centralized repo service like GitHub, sometimes you just have a local project you want to share with a friend or two. You can fire up a git repository server very quickly using the following command:
git daemon --reuseaddr --verbose --export-all --base-path=/path/to/root/of/repos
Your friend will then add the repo in question to his remotes
git remote add somerepo git://your.ip.address/project-folder-name
git fetch
Please see the `git help daemon` for further discussion on this topic.
Release management is all about branch management, and branching in git is easy. Here's the general workflow I recommend for managing releases
* Core committers commit bug fixes and features to master branch with commit messages "Ticket #123 --- short description of bug". Long running features are developed on separate branches and `merge --squash` into master.
* Outside contributors commit to forks, and have their changes merged in by core committers.
* A release is cut by creating a new branch from master, or by branching from the last release branch and cherry-picking selected changesets. The master branch is tagged at the release point.
* Emergency fixes to production are cherry-picked into the release branch.
## Chapter 5 - Release Management
### Creating the release branch
Let's say this is the first time you're creating a release. You've worked with your team to stabilize the code in *master*, and are now creating release *1.0*.
grb create 1.0
git push
git tag tag-1.0
git push --tags
Congratulations, you now have a 1.0 branch created, and a tag called *tag-1.0* and ready for release. Note that at this moment, the tag and the branch are identical. The difference is that the branch pointer may continue to evolve as it gains new commits for prod fixes, while the tag is there permanently for future reference to the branch point.
### Using cherry-pick to move bugfixes into a release
Your release is running in production, and you've found a bug. Let's commit the bugfix into *master*, and then cherry-pick the same patch into the branch.
git checkout master
# hack, hack, hack
git commit -a -m "Bug #123 - emergency prod fix"
git checkout 1.0
git cherry-pick -x master # or using my alias 'git cp master'
git push
Let's take a look at what just happened. We committed the fix into master, and then we used a git command called `cherry-pick`. This command copies a patch from one branch to another.
The `-x` switch asks git to put the original commit id into the commit message of the cherry-picked fix so that we can easier track where it came from. Note that `cherry-pick` takes an argument of a particular commit hash. Since we know that branches in git are simply aliases for commit hashes, we can just say *master* to refer to the last commit in the master branch.
Note also, that since `push` will push out all changes on matching branches to their remotes, both *master* and *1.0* will be updated on the remote. Fast and easy!
### Generating release changelogs
The gitalias file provided in the appendix offers a very handy changelog alias which generates a bulleted list of changes. Since you've tagged your last branch point, we can easily generate a list of changes from that branch point to the current HEAD of master:
git changelog tag-1.0..master
If you did not tag, you can find the original point at which the branch diverged, but I have found this is sometimes error prone. The `merge-base` command will give you the last commit which is shared by two branches:
git merge-base 1.0 master
You can then use that commit to generate your changelog
git changelog [commit obtained from merge-base]..master
A great way to introduce git into your organization is…not to! Your team or management can be resistant to change, but that doesn't mean you can't start reaping the benefits of git's fully offline repositories, fast logs, topic branches, and changeset management.
By using git-svn you can get all the benefits of git while pushing your commits to an svn repository. When you're ready, you can migrate to a fully git-based solution in only two commands.
## Chapter 6 - Sneaking Git Through The Backdoor
If you work in an organization where svn is firmly entrenched, and there are too many developers to make a smooth and sweeping transition, do not despair!
In this chapter, we'll learn how to start using git on top of svn transparently, so that you can benefit from speed and offline productivity, as well as how to migrate your repo once you're ready.
### Setting up git-svn to track a remote svn repository
With pure git, you use `git clone` to make a copy of someone's repository to do work on it. With svn, we use `git svn clone`.
git svn clone [svn-url]
Note that the initial clone command may take some time as it copies your entire subversion repo all the way to the beginning of time and creates an analogous git repo. The git repo typically takes up a fraction of the space that the original svn repo did.
After the command finishes, you have a standard git repo with one special feature. If you take a look at your `.git/config` file, you'll notice there is now an entry for the connection to svn:
[svn-remote "svn"]
url = http://url/to/your/svn/repo
fetch = trunk:refs/remotes/trunk
tags = tags/*:refs/remotes/tags/*
This enables you to push and pull changes from svn. However, instead of using the commands `git push` and `git pull` to do so, you will use `git svn dcommit` to push (equivalent to svn commit), and `git svn rebase` to pull (equivalent to svn update). While these commands have obscure names, they work similarly to `push` and `pull --rebase`. Note that you can make any number of commits locally and then `dcommit` to push them all as individual svn commits.
Now use `git branch -rv` to see the remote branches. Remember, as with any git repo you never work with remote branches directly. So if you're looking to work with a branch, make a local tracking branch for it.
git branch 1.1.2 branches/1.1.2
# hack
git commit -a -m "made changes on the branch"
git svn dcommit # goes to branch 1.1.2
For more on git-svn, please see
### Mapping non conventional svn layouts to git
If your project uses an unconventional branch layout in subversion, for example branches/1.0.1/module instead of module/branches/1.0.1, you can still use git-svn by making a modification to your .git/config file to properly map the branches. Note the special *** syntax in the branches line below.
```
[svn-remote "svn"]
url = http://company.com/svn/projects
fetch = trunk/project-foo:refs/remotes/project-foo/trunk
branches = branches/*/project-foo:refs/remotes/project-foo/branches/*
```
### Migrating to git: keeping svn and git in sync
From git's perspective, your git-svn repo is not different from any other git repo. So in order to push it out to a remote place, we follow the same steps we would for any git remote repo:
git remote add origin [github url]
git push
You can now get sneaky and start pulling changes from your team via svn, and pushing it to github:
git svn rebase
git push
Like magic. However, this is only recommended as a temporary solution because the svn rebase, like any rebase, will rewrite your commit id's, causing the possibility that anyone you're sharing code with via github may have a problem with your commits.
Nonetheless, this is an effective way to get your code up to github so that you can do code review comments until the rest of your team members are ready to switch to git. When they are, they can simply clone the repo url from github, and proceed as normal.
### A Note on Source Control Politics and Religion
The purpose of this chapter was to show you how you can start using git without having to convince your boss or your ops team that git is a good thing. However, be warned that once you
start using git, and have to collaborate with others that are on svn, you will quickly become frustrated at svn's lack of the features you've grown to love. This is good! That means you're
ready to lead the team to a transition. Having spent time learning git deeply, by reading this book and hopefully at least one of the other resources I pointed out, you should be prepared
to become the git expert in your organization if you want to help people transition.
The way I recommend leading the transition is from the bottom, by showing developers on a one by one basis, how you've got things set up and why you think git is cool. Be prepared that not everyone will invest the
time you have to learn the system. That means that people may run into complex problems and questions that you should be prepared to solve. Personally I take it as an opportunity to
improve my understanding of git internals every time someone does something crazy with rebase or reset and think they've totally broken their system :) Do not attempt to force git
from the top of an organization, as you'll be met with a lot of frustration. People are comfortable in their source control and they don't want to learn new systems without seeing the benefit first.
Show them the benefit on your machine, then invite them to transition theirs.
Once you have transitioned a handful of people to git, let them too become experts, and spread the git throughout the organization. Soon enough, most of the dev team will be using git on
top of svn. At this point, you can simply point this out, and lead the political transformation to pure git development. Github alleviates many concerns of having centralized repositories,
so whip out your credit card, get an account for a few bucks a month, and have at it. Good luck!
Copyright 2011, [Yan Pritzker](http://yanpritzker.com). All Rights Reserved.
### Appendix A - The .gitconfig
[color]
ui = true
[color "branch"]
current = yellow reverse
local = yellow
remote = green
[color "diff"]
meta = yellow bold
frag = magenta bold
old = red bold
new = green bold
[alias]
# add
a = add # add
chunkyadd = add --patch # stage commits chunk by chunk
# branch
b = branch -v # branch (verbose)
# commit
c = commit -m # commit with message
ca = commit -am # commit all with message
ci = commit # commit
amend = commit --amend # ammend your last commit
ammend = commit --amend # ammend your last commit
# checkout
co = checkout # checkout
nb = checkout -b # create and switch to a new branch (mnemonic: "git new branch branchname...")
# cherry-pick
cp = cherry-pick -x # grab a change from a branch
# diff
d = diff # diff unstaged changes
dc = diff --cached # diff staged changes
last = diff HEAD^ # diff last committed change
# log
l = log --graph --date=short
changes = log --pretty=format:\"%h %cr %cn %Cgreen%s%Creset\" --name-status
short = log --pretty=format:\"%h %cr %cn %Cgreen%s%Creset\"
changelog = log --pretty=format:\" * %s\"
shortnocolor = log --pretty=format:\"%h %cr %cn %s\"
# pull
pl = pull # pull
# push
ps = push # push
# rebase
rc = rebase --continue # continue rebase
rs = rebase --skip # skip rebase
# remote
r = remote -v # show remotes (verbose)
# reset
unstage = reset HEAD # remove files from index (tracking)
uncommit = reset --soft HEAD^ # go back before last commit, with files in uncommitted state
filelog = log -u # show changes to a file
mt = mergetool # fire up the merge tool
# stash
ss = stash # stash changes
sl = stash list # list stashes
sa = stash apply # apply stash (restore changes)
sd = stash drop # drop stashes (destory changes)
# status
s = status # status
st = status # status
stat = status # status
# tag
t = tag -n # show tags with lines of each tag message
# svn helpers
svnr = svn rebase
svnd = svn dcommit
svnl = svn log --oneline --show-commit
[format]
pretty = format:%C(blue)%ad%Creset %C(yellow)%h%C(green)%d%Creset %C(blue)%s %C(magenta) [%an]%Creset
[mergetool]
prompt = false
[mergetool "mvimdiff"]
cmd="mvim -c 'Gdiff' $MERGED" # use fugitive.vim for 3-way merge
keepbackup=false
[merge]
summary = true
verbosity = 1
tool = mvimdiff
[apply]
whitespace = nowarn
[branch]
autosetupmerge = true
[push]
# 'git push' will push the current branch to its tracking branch
# the usual default is to push all branches
default = tracking
[core]
autocrlf = false
editor = vim
excludesfile = ~/.yadr/git/gitignore
[advice]
statusHints = false
[diff]
# Git diff will use (i)ndex, (w)ork tree, (c)ommit and (o)bject
# instead of a/b/c/d as prefixes for patches
mnemonicprefix = true
[](https://bitdeli.com/free "Bitdeli Badge")
本源码包内暂不包含可直接显示的源代码文件,请下载源码包。